atmaCup#9 運営振り返り #atmaCup
みなさんこんばんは。atmaCup運営の nyk510 です。この記事では 2021/1/29~2/6にかけて開催しました atmaCup09 について運営サイドとして振り返っていければと思います。
atmaCupとは
atmaCupとは、データ解析・アルゴリズムソリューション・システム開発を行うベンチャー企業atma株式会社( https://atma.co.jp )が主催するデータコンペティションです。
参加者が会場に集まり、準備されたデータをテーマに沿って分析・予測しその精度を競っていただくイベントです。現在はCOVID-19 感染拡大を防止する観点から、基本的にオンラインで分析していただき、会場を用意する際にも十分に考慮した形での開催を行っています。今回の atmaCup#9 も完全オンラインにて行いました。
多数の企業様に協賛いただきました。
本コンペティションは、リテールAI研究会さまと共同開催であり、また多数の企業様に協賛をいただき開催の運びとなりました!
- 株式会社ロッテ
- カルビー株式会社
- キリンビール株式会社
- アサヒ飲料株式会社
- 株式会社日本アクセス
- 株式会社電通
- フクシマガリレイ株式会社
- 日清食品株式会社
- 株式会社トライアルホールディングス
- 株式会社True Data
- 日本マイクロソフト株式会社 (分析環境提供)
- Ledge AI (メディアスポンサー)
敬称略
データと課題の概要
atmaCup09ではトライアルさんの店舗で導入されているスマートショッピングカート(レジカートという愛称で呼ばれることもあります)のデータを使用しました。 スマートショッピングカートは、トライアルグループが開発をしたタブレットとバーコードリーダを搭載したセルフレジ機能つきの買い物カートのことです。これによってお客様は商品をスキャンしながら買物をすすめることができます。
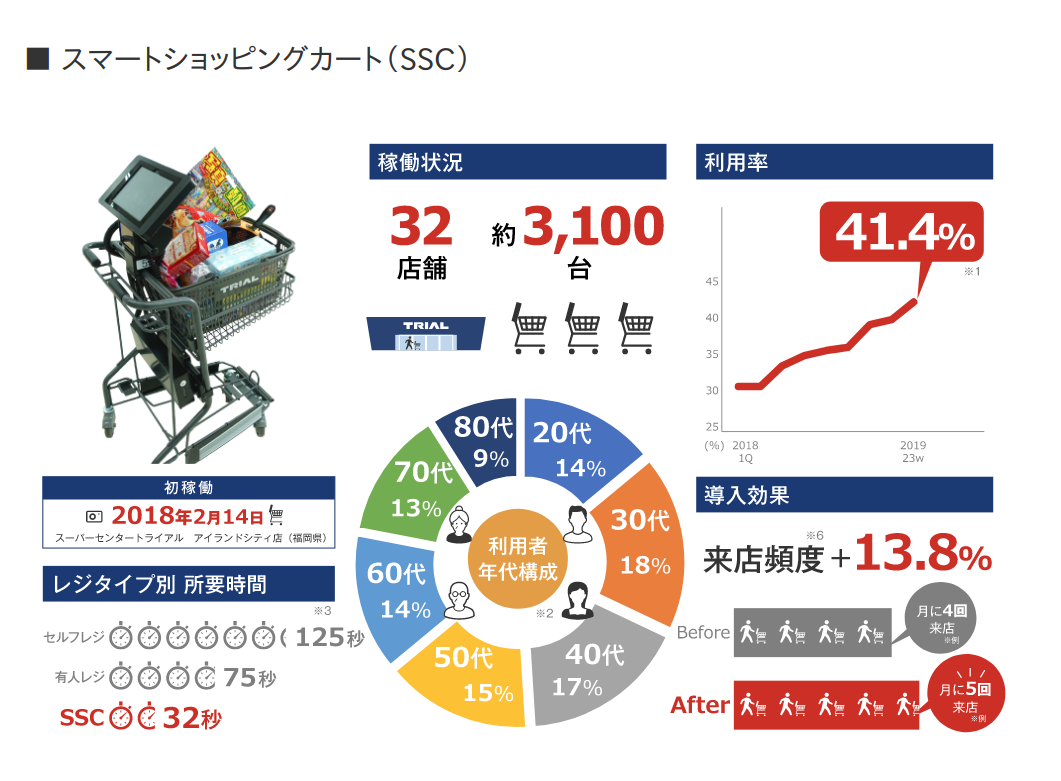
詳しく知りたい方は「トライアルのスマートショッピングカート、リテールAIカメラ https://www.trial-net.co.jp/cp/mediakit_ssc_aicamera/」や 「トライアルのAIは“店頭”で進化する https://www.trial-net.co.jp/cp/mediakit_ssc_aicamera/message.html」などご覧ください。
スマートショッピングカートは、お客さん目線で見た時、自分で買物を完結させられる点がとてもユニークなデバイスですが、データという観点でも、とてもユニークなデバイスです。
一般の会計レジで集められるデータは、何を・誰が・いつ会計したかという情報で、買物の順番や買い物途中の振る舞いについての情報を得ることはむずかしいです(POSや POSにユーザーが紐付いた ID-POS などが該当します)。
一方でカートではユーザーがその場で商品をスキャンしますから、どういう順番で買ったかという順番の情報がわかります。更には「商品を一度入れたけれどキャンセルをした」イベントや、カートではタブレット上にクーポン情報を表示し利用することができますので「買物と同時にどういうクーポンを閲覧したか」というイベントなど、会計には残らない情報を知ることが可能になります。
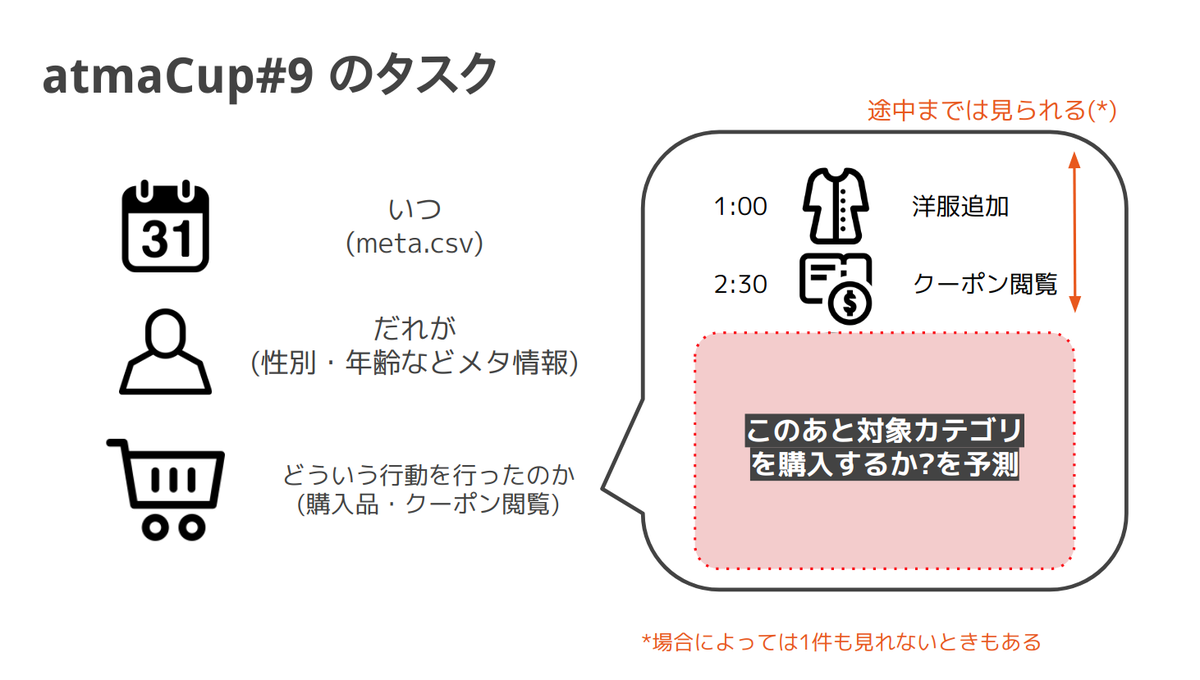
このカートのログデータをもとにして、買物の途中までの状態から、その後にそのユーザーが特定の商品を購入するかどうかの購買予測を行っていただきました。具体的には学習期間と定めた間では完全なるログデータをお渡しし、テスト期間のデータでは特定の時刻までの購買ログのみを渡して、その後特定のカテゴリを購入するのかをカテゴリごとに予測し、カテゴリごとの AUC 平均値 (MacroAUC) で評価します。
前回との違い
リテールAIさんとの前回のコンペ atmaCup#4 https://www.guruguru.science/competitions/9 では ID-POS データに対して同様の課題設定で取り組んでいただきました。こちらと比べると
- 厳密に時間がわかっているため、厳密にある時刻の買い物カゴ状態が再現できていること
- スマートショッピングカートならではの情報(購入順番・キャンセル・クーポンのイベント)が新しく追加されていること
の2点が大きな違いです。オンラインECならいざ知らず、リアル店舗で上記のような粒度のデータを得ることはスマートショッピングカートのようなデバイスがなければ不可能です。業務ではもちろん、コンペティションでもこの粒度のデータが公開されたことは世界をみても無いのではないでしょうか。大変貴重なデータを出していただいたトライアル様には大変感謝です 🙏
課題がとけると嬉しいこと
カートの状態からユーザーがかわなさそうなものがわかればユーザーごとに何を出せばいいかを判断する際の有益な情報になります。これらの情報を使うことでよりユーザーに気に入ってもらいやすいクーポンを表示するなど、ユーザーごとの体験を洗練させてより楽しく買物をしてもらうためのファーストステップとなります。
また予測に用いられている特徴重要度などを見ることで、どの商品を買いやすい場面は何と関係しているのかといった傾向をつかむことができます。これによって、例えば別の商品との併売傾向がわかったり、クーポンをみたときの影響度合いなどを定量的に判断することができ、新しい商品開発や売り場の配置を考える際の材料として使うことが可能です。今回は特にレジカート独自の情報がありますので、ID-POSの分析以上に踏み込んで関係性を議論できます。
コンペを振り返って
たいへん多数の方々に参加いただきました!
NDAを締結する必要があるハードルがあり、かつデータもレコード数が多く、自由度が高い難しい設定でしたが、合計で 268チーム ・ 2296回の submission をして頂けました!! 多数の方々に参加・コミット頂けたこと、とてもうれしく思います。ありがとうございました!!

活発にディスカッションをしていただきました!
今回は特にデータが完全なログデータであり、よくある教師ありの枠組みを作るのが難しいデータで難易度が高くディスカッションまでやっている余裕がない〜となるのではないかなと危惧していたのですが、多数の投稿でアイディアを共有していただきました。NDAの関係で中身のことが言えないのが残念ですが、協賛企業さんに絡んだ?購買データに関するEDAが多数あったり、純粋に読んでいてとても楽しい投稿ばかりでした。
コンペ終了後にも、多数の方に自分の取り組みをまとめて公開していただきました。運営としては、データをどういうふうに見たのかという部分もとても参考になりますし参加者さん同士の振り返りの機会としてもとても有意義であると思っていますので、このようにディスカッションを使っていただいて嬉しい限りです。
そんななか nyk510賞を取られたのは hakubishin3 さんでした!! おめでとうございます🎉 *1

コンペ序盤にでたディスカッションで、データをパキっと加工するためのユーティリティクラスの作成を共有されたものでした。今回は過去に比べてとても自由度が高いデータでしたので、こちらのディスカッションのクラスを使って分析をされたかたも多くいらっしゃったのではないかと思います。こういう情報を出して頂けるのはみなさんハッピーになるので、とてもうれしいですね!
初心者向け講座を開催しました
atmaCup はデータ分析・コンペ初心者のかたの参加を歓迎していて、毎回左記の方々を対象として、初心者向け講座を開催しています。今回も nyk510 から初心者向け講座を2回に分けて開催しました。 講座#1は課題についての確認と submission の作成・#2では EDA とその情報を使った特徴量作成とその管理方法についてご紹介しました。
AzureML環境を提供しました。
「Azure使いたい枠!」として 8core32GB RAM相当のマシンが利用できる環境を提供しました。AzureMLは難しい設定を何もしなくても、セキュアな環境に jupyter notebook 環境を用意できる個人的にも推しのナイスなサービスです。Kagglerはじめとする機械学習勢は基本的にGCPを使われる方が多いと思うのですが、Azureもやれる娘であることが少しでも伝わったらよいなーと思います。*2
最終順位
最終順位は以下のようになりました! 優勝された pao さん、2nd nakama さん, 3rd senkin13 + lemming さんおめでとうございます🎉 (paoさんはなんとこれで通算3回めの優勝です、お強い…)
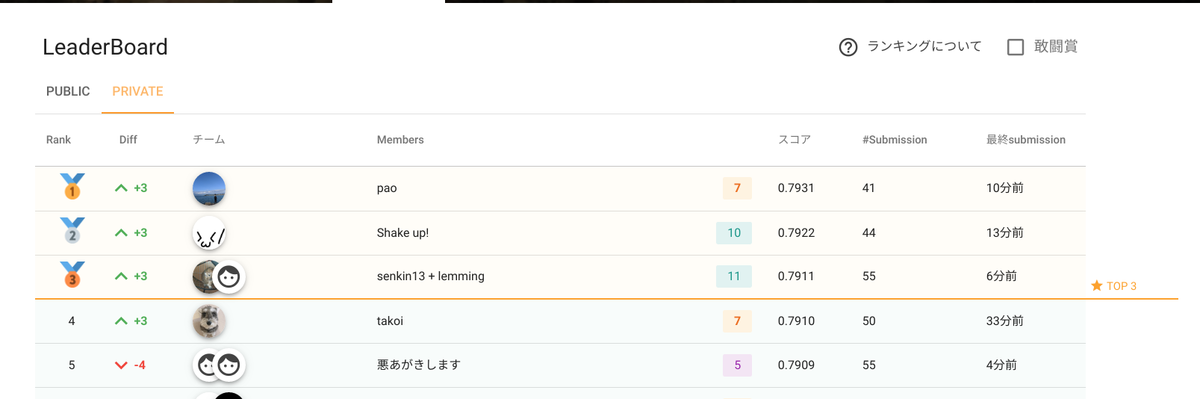
終盤のデッドヒートはコンペサイト「ぐるぐる」の summary tab からも確認できますので、興味ある方はごらんください。 https://www.guruguru.science/competitions/14/summary
ソリューションをみていても、予測する対象ごとに細かくモデルを分けているチーム・MLPなどのNNモデルとのアンサンブルを行なうチーム・更には transformer を使ったチームなど、多種多様なアプローチがあったことが印象的でした。
また、チームごとの予測カテゴリごとの性能を比較しても特定のカテゴリは強いモデルがいたり、反対にまんべんなく良いスコアがでているモデルがあったりと、取り組みの多様さが出力の多様さにもつながっていて、参加者さんの創意工夫が遺憾なく発揮されていたコンペティションだったように感じています。
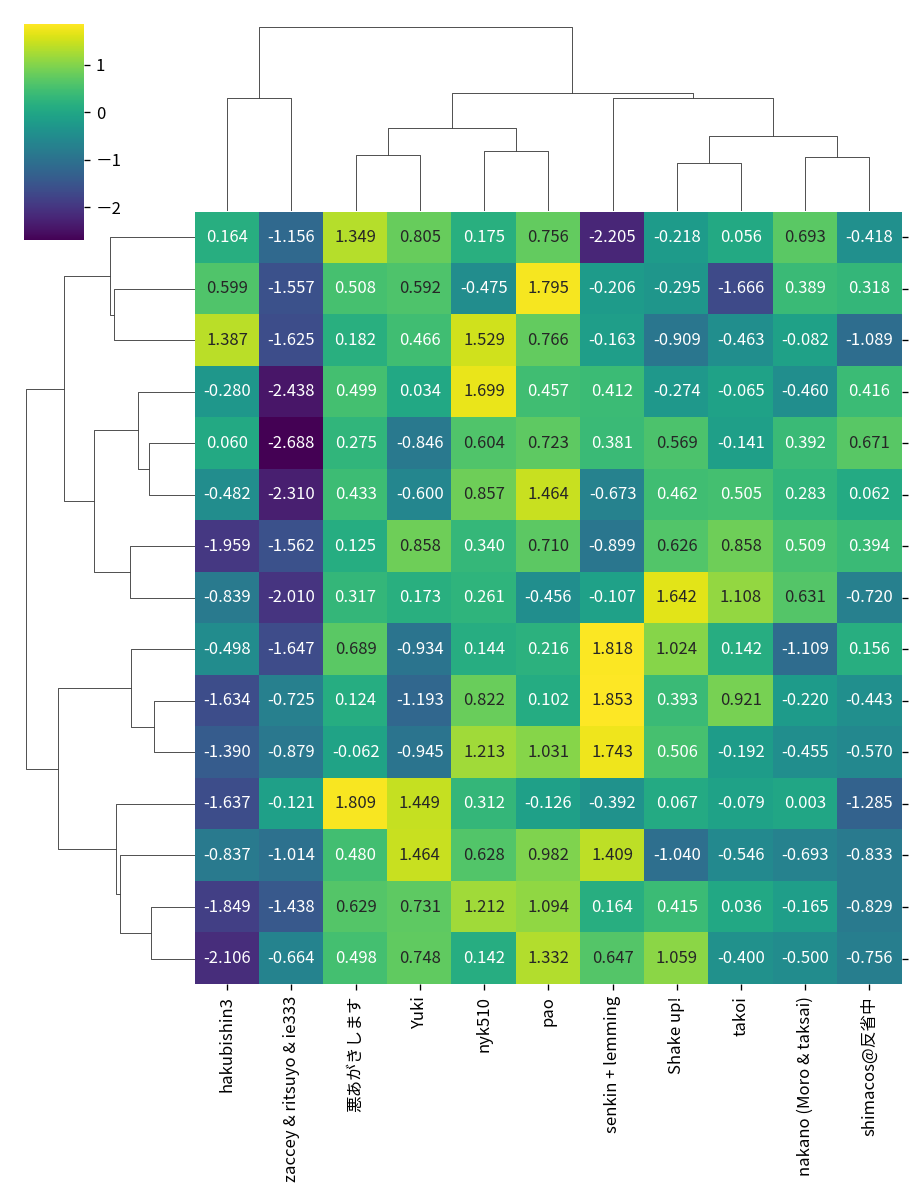
現在私の方で結果を調査中ではありますが、面白い傾向としてすべてのモデルが正解しているデータがある一方で、全員同じように間違えているデータがあったり、反対に一部モデルだけが当てられているデータがあったりすることもわかっています。これらのデータに対応する買物ログを注意深く見ることで、なぜモデルが外しているのかの気持ちを考えて、ユーザーの買物傾向を深く知るための道具にすることが出来ないか、などを考えています。
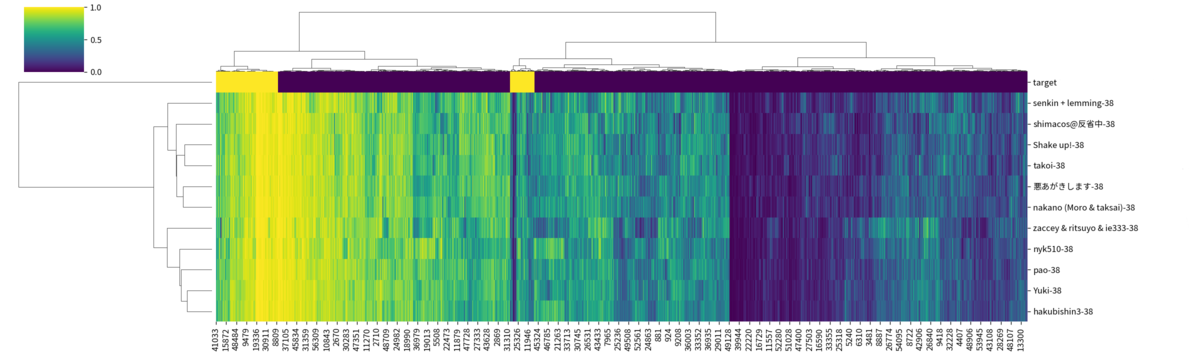
アウトプットが多様なこともあって、上記以外にもたくさんの見方と分析の切り口があり、分析途中ですが私としても大変ワクワクしてます! 皆さん本当にありがとうございましたmm*3
振り返り会を開催しました
atmaCupでは、コンペ終了後にコンペ内容にかんしてあれこれとお話する振り返り会を毎回開催しており、今回も終了後2週間後に開催しました。

優勝された pao さんにはソリューションとコンペ中の取り組みについてのお話をしていただきました。コンペ会期中の気持ちやそのばその場で何をするかについての話はなかなか聞く機会がないですので、僕自身とても参考になりました。

またLT枠として、takapyさんに item2vec で商品を埋め込んで予測するときの手法ごとの性能の違いについてのお話をしていただきました。こちらもとても興味深い結果がでていて、聴講枠参加者さんからの質問もいくつもでて活発な議論になりました。

最後に
今回も皆さん多数参加いただきありがとうございました!
次回の atmaCup#10 も開催決定しております。こちらは初心者歓迎コンペとなっていて、#9同様に、データ分析に慣れていない方向けにデータの見方やモデルの作り方・submission作成までをフォローする初心者向けのセッションを開催予定です。今まで「コンペはハードル高いな」と思っていた方も気軽に参加いただければとてもうれしいです。
それでは、次回の atmaCup でお会いしましょう🌟
【お知らせ】 取締役山口がデータサイエンティストとして携わった空間デザイン作品が、心斎橋パルコに展示されます!



弊社取締役山口がデータサイエンティストとして作品に携わった、KiQの菊地あかねがディレクションする空間が心斎橋パルコ5Fフロアに2020年11月に完成。 この作品は、大阪の様々な風景を撮影し、そこに写り込んだ色をAI・機械学習により抽出、それを菊地氏の感性によりかさねの色目、折り紙のように見立て空間デザインに実装しています。現代の大阪ならではの空気や景色といった暗黙知の領域を表現するデータビジュアライズを、商空間の壁や天井などの内装デザインに実装した作品です。
山口は主に街の風景の写真から色と順序、並びにその割合を生成するアルゴリズムを担当いたしました。以下本人からのコメントです。
ひょんなことから始まったプロジェクトでした。クリエイティブ視点による高度な感性から機械学習でのアウトプットをどうアートにするかの部分に関してはとても苦労しましたが、様々な案やプロトタイプを出しつつKiQの菊地氏からディレクション・意見いただくことで、最終的に磨きのかかった良い空間作品に仕上がったのではないかと思っています。制作に携わっていただいた皆様に感謝申し上げます、ありがとうございました!!大阪・心斎橋にお立ち寄りの際は是非足を運んでいただけると幸いです!
KiQ / https://kiq.ne.jp/ 心斎橋パルコ / https://shinsaibashi.parco.jp/
- Direction: 菊地あかね ( KiQ )
- Design: 征矢野優太、藤山愛弓 ( KiQ )
- Data Scientist: 山口貴大 ( atma )
- Art: 柳澤顕 ( ARTCOURT Gallery )
- Camera : 松下和暉
- Construction: 竹中工務店,パルコスペースシステムズ
アルゴリズムについて
写真から色を取り出すアルゴリズムは大きくわけて
- 写真内に存在する色をクラスタリングし代表的な色を選択
- 写真内で代表色ごとに、色の割合を計算
- 色を並び替え、割合に応じて幅を調整して描画
という3つのフローから構成されています。

クラスタリングや割合計算には機械学習を用いていますが、ベーシックな機械学習アルゴリズムをそのまま使うのではなく、クラスタの計算方法・重み付け方法・ハイパパラメータ等、人間が視覚で感じる特徴に近づくよう独自の調整を行い、より写真が持つ、色としての雰囲気が伝わるような工夫を加えています。
山口コメント
業務でも機械学習やAIを作成することは頻繁にありますが、その場合性能改善が目的となる場合が多く、今回のように人が視覚やカメラを通して表現される時の感覚 (特定の写真らしさが色に出ているか) に訴えることができるかどうか、という主観に大きく依存する観点ではありません。
今回の「その1枚の写真らしい色の組み合わせを作る」という問題は、主観に依存する部分も大きい、正解がないタスクでしたので、とにかくたくさん作ってみて良いものを選んでいく方法が最適だと考えました。はじめナイーブに思いつくアルゴリズムからスタートして、アウトプットを自分やKiQチームに確認していただいてフィードバックをもらい、再度アルゴリズムやパラメータを修正・場合によっては全体のフロー自体を挿げ替えというPDCAを高速に回すことで、ブラッシュアップを図りました。
通常お仕事でやる機械学習はアウトプットを数値化して評価できるよう設計することからスタートすることが基本ですので、今回通常と大きく異なった観点での思考を求められ大変な部分は多くありましたが、人間と機械学習の在り方の違いとその共存、データビジュアライズと機械学習を組み合わせていく可能性に触れることができとても楽しい時間でした。
#7 CA x #atmaCup atma社員の参加記録
はじめまして、atma社員の木原です。
(誰?となった方は私の簡単な自己紹介は 弊社HP にありますので、よかったらご覧ください!)
私はatmaに入社する前から、atmaCupに参加していたかなりのatmaCup好きです。
本記事は弊社が開催しているデータコンペティション「#7 CA x atmaCup」に一般参加者として参加してみましたので、その感想などを書いていきたいと思います。
もちろん、他の参加者の方と同様に私はatmaCupが始まるまで課題やデータについては全く知らない状態で参加しています。
内容としては、まだatmaCupに参加されたことない方がatmaCupでどんなことをやっているのかというイメージを少しでも持っていただけるように書いていきたいと思います。
atmaCupの概要
まず、初めに少しだけatmaCupの概要を説明させていただきます。
atmaCupは毎回様々な法人・企業様とコラボをさせていただきコラボをしていただいた企業様からデータを提供していただくことで、そのデータを参加者の皆様に分析していただき、その分析スキルを競い合っていただくイベントになります。
参加者の方の順位は、コンペティションごとに定められた評価指標によってデータ分析の精度にスコアを付けることで決定しています。
この形式は海外の有名なデータコンペティションサイト「Kaggle」と、非常に似た形式であるため、データ分析に興味のある方にとっては馴染みやすい形式になっていると思います。
分析するデータに関しては、提供していただくデータによっては画像データや時系列データなどが含まれていることもあります。
また、扱うデータの分野がビジネスであったり、科学であったりコンペティションごとに異なり、毎回違った発想でデータを分析していく必要があるなどの楽しみもあります。
一方で、分析に使用するために提供していただくデータにはコラボ先の企業様が収集した貴重なデータも多く、基本的にはデータに関してはatmaCupの参加者内でのみしか議論や言及をしてはいけないことになっています。
そのため、atmaCupに参加されたことがない方にとってはどんなコンペティションなのか情報が伝わりにくくなっているのではないかと思っています。
ただ、コンペティション内では、データ分析に関する有益な情報が多く公開されているので、参加経験の無い方はまずは1度試しにぜひ参加していただきたいと考えています。

今回のコンペティションについて

今回は開催期間が11/15(日) ~ 11/21(土)と約1週間あり、開会式から閉会式まで全てオンラインで実施されました。
データについてはサイバーエージェント AI事業本部 (https://cyberagent.ai/) 様とコラボしており、データ分析の課題は「広告経由のCV予測」でした。
あるユーザーが広告が表示されてから、その広告経由でCVが発生するかどうかを予測する二値分類のデータ分析で、データはテーブルデータのみでした。
また、予想したいCVの発生はデータ全体の中では頻度が少ないデータとなっている不均衡な二値分類となっていました。
そのため、評価指標はPR-AUCが用いられており、いかに数少ないCVの発生を的確に予想できるかが重要な課題となります。
私のコンペティションの流れと感想
参加者によってatmaCupの参加の仕方は大きく異なると思いますが、ここではatmaCupでどんなことをやっているのかを少しでもイメージしていただけるように、一例として私の参加の仕方を振り返ってみたいと思います。
- 日曜日(初日)
- 開会式に参加して、課題とデータを確認
- 広告に関する知識が全く無かったため、データ分析の前に広告について調べる(CVが何かも知らない状態)
- この段階ではまだコードは書いていない
- とにかくデータの量が多くて、びっくりしていた
- 月曜日
- 初心者講座#1を元にベースとなるコードを作成
- ディスカッションの内容に全て目を通す (ディスカッションとは参加者の方が自由にデータについての議論を投稿することができる場です)
- 最初のサブミッション (サブミッションとは今のデータ分析の精度が評価指標に基づいてどの程度のscoreがつくのかを確認する方法です。また、このスコアによってatmaCup中の暫定順位が決められます)
- データの量が多く、計算にとても時間がかかるので効率が良い方法がないかを探し始める
- 火曜日
- 初心者講座#2を視聴
- ディスカッションの内容などを参考に自分なりに特徴量をどんどん作っていく
- 水曜日 ~ 木曜日
- 常にディスカッションには目を通して、良い方法がないかを検討
- スコアが上がりそうな方法を思いついたものからどんどん試していく
- 計算時間を短縮する方法が思いつけなかったため、寝る前や仕事中に計算するように調整
- 金曜日 ~ 土曜日 (最終日)
- 最後のラストスパートとして、考えていたアイディアを一通り試してみる
- 土曜日は予定があり、アイディアが一旦尽きたので実質的には金曜日の深夜で作業終了
といった流れでした。
今回のatmaCupは、第一印象としては「データの量が多い」と「広告の仕組みがよくわからない」からのスタートでしたが、広告の仕組みについては異分野のことを能動的に調べるきっかけとなり、広告について理解が深まったことはとても良かったと思います。
広告について調べている間はずっと何かアイディアとして使える情報は無いかを考えながら調べていたため、とても集中して取り組むことが出来て有意義でした。
データの量が多かったことについては最後まで計算に時間を取られてしまいずっと頭を悩ませていましたが、atmaCup終了後のディスカッションなどを見ると、他の参加者の方々がどのように工夫をして大量のデータを処理していたかなどを知ることが出来て、とても勉強になりました。
今まであまり考えていなかったのですが、いかに少ないリソースで効率的に大量のデータを処理するということも現実的にはとても重要なことだなと気づくことができました。
総じて、なかなか濃い1週間を過ごせたのかなと感じています。 一緒に参加していた参加者の方々、いろいろな学びをありがとうございました。
atmaCupのススメ
最後に私の思っているatmaCupのオススメしたいところをお伝えして終わろうかと思います。
まず、私が個人的に思っているatmaCupにぜひ参加していただきたいと思っている対象者は
のような比較的データ分析を始めて日が浅い方々です。(ちなみに私もこの対象に含まれます)
atmaCupでは、このようなデータ分析の初学者の方にとって、とても良い環境が整っているのではないかと感じています。
私としては、下記の3つが特に初学者にとって嬉しいなと感じた理由になります。
1.全て日本語
当然といえば、当然なのですがatmaCupは全て日本語です。
データ分析を始めたてであれば、分からないことが非常に多くあると思いますが、 そのような状態でkaggleなどの海外のコンペサイトなどを利用すると英語も理解する必要が出てきてしまい余分な労力がかかりやすく、データ分析を学ぶためのハードルが高くなってしまいやすいです。
そのため、データ分析以外のことにはできるだけ労力がかからないようにすることが大事だと思いますが、その点では全て日本語で運営しているatmaCupはうってつけです。
2.初心者向けの講座
atmaCup開催中の期間には、弊社のデータサイエンティストの山口による初心者向けの講座があります。
この講座では山口がYoutubeを使用して、その時の課題やデータに沿って、どのようなデータ分析を行えば良いかの基本的な内容を解説してくれるものです。 また、基本的なデータ分析の後にはどのような視点でよりデータ分析の精度を上げていくことができるのかなども解説しています。
さらに、講座で解説に使用したコードは全員に公開されるので、参加者が自分の手元で実際にコードを触りながらカスタマイズしていくことができるため、 まだ不慣れな人であってもデータ分析の要所を掴むには最適となっています。
3.ディスカッション
atmaCupは比較的短い期間(1週間以内程度)での開催が多いため、参加者の方々は開催中は非常に熱心に取り組んでいただく方が多いです。
そのおかげもあり、短い期間ながらに多くのディスカッションが投稿され、様々なデータ分析の知見を学ぶことが出来ます。
このディスカッションは本当に学ぶことが多く、勉強になります。
自分が今分析している課題に対して、リアルタイムでどんどんディスカッションが投稿されていくので、他の参加者の方がどういった視点でデータを見ているのか、 どういう分析方法を試そうとしているのかなど自分の考えと照らし合わせて見ることで、今までになかった新しい視点でデータを見ることができるようになると思います。
以上、私が思うatmaCupをオススメしたい理由でした。
それでは、次のatmaCupでまた会いましょう!
#6 Sansan x atmaCup を開催しました。
おこんばんは。取締役の山口です。少し遅くなってしまいましたが Sansan 様と #6 Sansan x atmaCup を開催しました。

第6回目となる今回はコロナウイルスの影響もあり基本オンライン・最終日LTを行なう方だけがオフライン参加という形での開催となりました。
お題はネットワークに関するデータからの出題で、とても Sansan さんらしいデータかつ課題になっており、とても珍しいものでした。
参加された方も新鮮みがあって面白かったという意見が多かったように思います。(同時にあまり扱わないデータなので大変でした、という意見もありました。僕も課題設計フェーズで相当勉強したので最初のキャッチアップは大変だったのかなとは思います)
初心者向け講座 #1
atmaCup はデータ分析・コンペ初心者のかたの参加を歓迎していて、毎回そういった方々対象の初心者向け講座を開催しています。今回も nyk510 から初心者向け講座を2回に分けて開催しました。 講座#1はデータの見方についての講座で pandas-profiling によるデータ全体の可視化・Train/Testでのデータのズレについて・時系列データの取り扱いと可視化について紹介しました。
この配信諸事情があり闇の中からの配信となりました。
光るデータサイエンティストと山城 @nyker_goto pic.twitter.com/JEPDIsYH00
— OpenJNY (@OpenJNY) 2020年10月20日
↑の写真だとだいぶ綺麗に見えますが、実際の配信画面は↓の感じで真っ暗です笑

初心者向け講座 #2
講座#2は実際にsubmissionをするまでについてを解説しました。特徴量作成の方法と壊れにくいコードの書き方、LightGBMによるモデル作成、特徴重要度の確認方法など紹介しました。
活発なディスカッション
コンペで使っているぐるぐるではディスカッション機能がついています(コンペ参加者が閲覧できる掲示板のようなものです)。 今回も序盤からいろいろな方が知見をディスカッション上で共有してくれました! 特に @nino_pira さんのGCNに関するdiscussionはコード付きでGCNを動かすnotebookで「こんなのだしていいのか…」と思ったのを覚えています。(最終的に nino_pira さんはこの post で nyk510賞を獲得されました。おめでとうございます🎉)
「皆さんの知見共有のために!!」と思いGCNの実装例をディスカッションに投稿
— にのぴら (@nino_pira) 2020年10月22日
精度悪すぎて公開するか悩みましたが 冒頭に書いてる通り本コードを改良してPublic0.77まで到達しております(小声)
(ディスカッションのURLをツイートしても参加者以外は見れないはず)#atmaCup https://t.co/TUQwuBdCHW
閉会式
閉会式は Sansan 本社からの配信という形で行いました。僕もSansanさんオフィスに伺って配信に参加しました。Sansanさんのオフィスとても綺麗で感動していました(現代美術館かなにかか?っていうぐらい綺麗)。
じゃん! pic.twitter.com/e7sDAcasU4
— nyker_goto (@nyker_goto) 2020年10月31日
今回のコンペでは学生1/2/3位と社会人1/2/3位、加えて総合での1位に賞金が授与されました。
学生の部: 3位: tonak_ai さん / 2位 T0m さん / 1位 NmaViv さん 社会人の部では 3位: --pao-- さん / 2位 mrkmakr さん / 1位 takoi さんでした!


また総合ランキングは社会人の3名がそのままランクインし、総合優勝も takoi さんとなりました!🎉
総合ランキングと時系列の推移はぐるぐるの下記ページからも閲覧できます。 https://www.guruguru.science/competitions/11/summary
LT大会
今回はコンペ終了後に取り組み内容等に関することを発表するLT大会が用意されていました。 LT大会は学生・社会人の枠で数名ずつ発表を行い、DSOCの研究員の皆様で審査を行い、学生・社会人それぞれに対して優秀者を決定するという流れです。
どの発表もとてもレベルが高かったのですが、優秀者に選ばれたのは 学生 tatei さん / 社会人 u++ さんのお二人でした! おめでとうございます🎉
LT大会で最優秀賞を頂きました。次はコンペで勝てるよう頑張ります。運営の方々、企画ありがとうございました🙏 #atmaCup pic.twitter.com/fovxXoXMBY
— u++ (@upura0) 2020年10月31日
こちら Sansan さん側のご提案で企画した、はじめての試みだったのですが皆さんの発表のレベルがとても高く、コンペの内容に関して理解がぐっと深まったように感じました。今後も機会があれば同様の枠を用意して開催できればと考えています。
僕も審査員として参加させていただいたのですが、みなさんの発表のレベルに応えなくてはと思って、特に発表するわけではないのにかなり緊張していたのが思い出されます。
また当日、発表枠に空きが出て急遽LTを募集したのですが nekoumei さん / @nino_pira さんに参加いただきました、こちらもありがとうございましたmm
振り返り回
今回も恒例の振り返り回を Sansan さん主催で別日に開催しました。オンラインオフライン合わせて 150 人を超える応募があり、入賞者の T0m-y さん、優勝の takoi さんから solution の解説発表をしていただきました。
データコンペティション中はどうしてもやっていることと結果の対応関係が発散しがちなのですが、お二人共取り組み内容がとても整理されていて流石入賞者は違うなと思います。
また Sansan DSOC 所属の黒木さんからはグラフ分析の基礎から実際にSansanで用いられているグラフに関するアルゴリズムについての解説をしていただきました。僕自信グラフについての網羅的知識がなかったのでとても参考になりました。
どちらもSpeakerdeck上からアクセスできますので是非ご覧ください!
最後に
今回も多数の方に参加いただいて、Discussion・LTなど盛り上げて頂いてありがとうございました。 また共催の Sansan さんには課題設計のフェーズから手伝っていただき、問題設定の検証やデータをどこまでオープンにするかなど、私の方から無理を承知で多数お願いしたのにもかかわらず快くご調整いただきました。大変ありがとうございました。
atmaCupは今後も開催予定です。データ分析慣れている方から、初心者の方まで、誰でも参加して学びがあって楽しいコンペになるよう頑張っていきます。少しでも興味あるよーという方は是非参加いただけると幸いです!
主催者から見た #atmaCup 5 は、データ分析のお祭りのようなコンペでした。
atma株式会社で取締役(あとデータサイエンティストとかエンジニアとかもろもろ)をしています、山口(@nyker_goto)です。 先日 5/29 ~ 6/6 にかけて atmaCup#5 を開催しました。コンペの雰囲気は twitter の hashtag #atmaCup や参加者さんの素敵な参加レポなど見ていただけると雰囲気を感じてもらえると思っています。
upura.hatenablog.com takaito0423.hatenablog.com agtn.hatenablog.com amalog.hateblo.jp nonbiri-tereka.hatenablog.com
公式の振り返りは atmaCup#5 開催レポート #atmaCup - atma-inc__blog こちらから。
このエントリでは運営とコンペ設計にかかわらせてもらっている nyker_goto の立場から今回のコンペ atmaCup#5 について振り返っていきたいと思います(データについては秘密保持の関係上細かいことは述べられないので、ふわっとした記述になることご容赦ください)。
atmaCup とは
そもそも atmaCup は atma 株式会社が主催する、オンサイトデータコンペです。
オンサイトデータコンペとは 実際に会場に集まり、準備されたデータをテーマに沿って分析・予測を行い、 その精度を競うイベントです。全員で一斉にスタートし、短い時間で決着するため 参加者のスキルがオンラインのデータコンペより強く結果に表れます。 実際に顔を合わせて分析を行うため、コンペ終了後に上位者に直接質問できることも特徴です。 atmaCup用コンペサイトぐるぐる https://www.guruguru.ml/ より引用
Kaggle など他のコンペティションでは期間が数カ月ですが atmaCup では比較的時間が短い (1日あるいは一週間) ため、素早い分析と実装能力が求められます。また通常は実際に同じ場所に集まって分析をしてもらうので、終わったあとに参加者同士で集まって解法について話をできるのも特徴です。
今回はじめてだったことが2つあります。1つがテーマが学術業界からの出題であったこと、もうひとつが完全オンライン開催であったことです。
初の学術業界からの出題
今回はじめて学術系テーマからの出題でした。若干大げさですが、産学連携なコンペティションだったと言えるかもしれません。
僕自信、データ分析は実際に応用し価値を出してこそはじめて意味があると思っています。その文脈で言えば、今回の課題は学術的・ひいては社会的にインパクトを与えられる課題でしたから、これを多数のデータ分析者が解いて良いモデルや予測のための知見が貯まることは非常に価値が高いことですし、その場を atmaCup が提供できたことをとてもうれしく思っています。
今後もっとこのような機会が広がってくれれば良いなと感じていますし、もちろん atmaCup でも引き続き取り組んでいきたいと思っています。とはいえ課題もあり、産の側からするとどうしても予算の問題が出てきてしまう (今回は手弁当的に開催となりましたが、持続可能性を考えるとずっとそうしてられないのも事実なのが世知辛いところです。特に弊社のような小さい会社だと特に。) ので、このあたりうまく解決できるスキームができれば良いなと模索しているところです。
初の完全オンライン開催
今回はコロナウィルスの影響もあり、完全オンラインでの開催となりました。過去開催ではオンライン推奨(atmaCup#4)はあったものの、基本的にはオフライン会場をメインとして進行していました。実際僕も会場に行って司会進行など行っていました。
atmaCupは時間と場所が決められているコンペで、それゆえに終わったあとの懇親会で参加者同士で実際に何をやったかを熱量(と記憶)があるうちに対面で議論できるのが面白いところの一つだと考えています。 これは自分が kaggle days tokyo に参加したときの経験やその他オンサイトのコンペに参加した方からのヒアリングでも楽しい要素の一つとして挙げられることが多い項目です。ゆえに今回完全オンラインになり、オフラインだったからよかった要素が完全オンラインでなくなってしまわないかという不安がありつつの開催でした。

しかしこれは良い意味で裏切られました。告知の段階で予想を大きく上回る300人以上の応募をいただき、またデータの不備でご迷惑をお掛けしたのにもかかわらず、開催期間中のディスカッション上での活発な議論や twitter での緑の画面報告*1など、客観的に見ても過去最大規模に盛り上がったコンペだったと思います。
とくに twitter でのハッシュタグ投稿がとても活発で、過去最もお祭りな感じがあったコンペでした。 これは運営だけでは作れない空気感であって、ひとえに参加者さんのコンペを楽しもうという思いによって作られたものだなと感じています。本当にありがとうございました。
🎉 ディスカッションの盛り上がり

ぐるぐるには Kaggle などと同じくディスカッションの機能があります。ディスカッションとは参加者さん同士でコンペのデータや分析手法などについて議論する掲示板のようなものです。今回合計で 78 件のディスカッションが作成され過去最大となりました。 データの機密性ゆえ参加者さん以外にお見せできないのが残念ですが、基礎的な分析をするコードを共有したものから、運営が唸るような波形に関するドメイン知識を満載に盛り込んだディスカッションなどなどバラエティに富んでいて僕も毎日新しいディスカッションを見るのが楽しみでした。
🎉 過去最大の Submission 数
#atmaCup ついに3000submissionです🎉 pic.twitter.com/nKoBkHred2
— nyker_goto (@nyker_goto) June 5, 2020
(残り時間19時間での tweet。 このとき3000submitを超えて喜んでいるがここから更に1600増える。)
submission 数は 4000 超 (#4602)でした。初回の total submission が 114 だったのを考えると遠くに来たものだなあと考えさせられます。
特に最終日の submission 数は本当に多くて、ぐるぐるの AWS Metrics を見るとその様子が露骨にわかって面白いです。submission 〆切後にはしばらくAPIがダウンするという事態も発生してしまいました、申し訳ありませんmm どうやら僕の設定が悪くてスケーリングが間に合わなかったようです。

submission はちゃんと課題に取り組まないと増えないゆえ、課題に取り組むモチベーションが最も表れる数字であると考えています。 コンペ中の僕の目標の一つは submission を増やすことで、特に 0 submit のコンペに慣れていない方が submit できるためにはどうしたら良いかなーということを考えつつチュートリアルを作っていたりします。
今回は完全オンラインで、オフラインに比べるとコミットメントがゆるいにもかかわらず 188 / 218 (85%以上! 100% まであとちょっと👊) のチームに submit していただきました。また特に上位チームを始めとしてチームの submit 上限まで submit しているチームも多く参加者さんの熱い思いを感じられました。ありがとうございました!!
🤔 今後のオンライン対応について
完全オンラインになったことで、大阪・東京から離れたところに住んでいる方も参加できるようになり (なんとアメリカからも!参加いただきました)、多数の応募をいただけたことで盛り上がりが加速したようにも感じていて、オンライン開催は悪いところばかりではないなと重う次第です。
とはいえ閉会式などしているとやはり最後の懇親会ぐらいはやりたいなー(もうちょっと気軽に解法を共有できる場がほしい)とも思えたので、次回以降はリアルとオンラインのバランスを考えつつ決めていければなと思っています。
個人的感想: ぐるぐるのリアルタイム更新について
ぐるぐるは atmaCupではコンペ用のサイト(submissionなどを行なうシステムを含んだウェブアプリケーション) のことです。このサイトは主に僕が開発を担当しています。今回開催に先立っていろいろと準備が間に合わなかったこともあり、ひじょーによろしくないのですが開催途中にコンペサイトの更新をバンバンやっていました(もちろん検証環境でテストなどやったうえでではありますが、よくはない)。普通ならお叱りを受けるところだと思うのですが特に苦情もなくみなさん優しくてありがとうという気持ちです……
あと更新した部分を twitter などで報告してくれるのも開発者としてとてもモチベーションが上がりました、本当にありがとうございますmm 今後も使って楽しいシステムになるように更新していきますのでよろしくお願いいたします😆 こうしてほしいなど意見があれば気軽に twitter で @nyker_goto 宛に reply をいただければ、爆速で実装したいと思います。
最後に
次回 atmaCup#6 も企画中です!! 参加したことある方は是非リピート参加を、気になってるけど出たことない〜という人も気軽に参加してください! ;) (次回もデータ分析経験がない方でも submission まで出来るようなチュートリアルを行う予定です。分析コンペに出たことがない・分析経験があまりない方も気軽に参加いただけると嬉しいです。)
募集は connpass の atmaのページ や atma twitter アカウント で告知をする予定です。良ければフォローしてください!
(僕のアカウント @nyker_goto も事実上会社の告知アカウントなのでこっちでも大丈夫です)
おまけ
コンペ中、チーム名大喜利が自然発生していたのですが、どのチームもセンスがあってとても楽しかったです! こういうのもなんだかお祭りな感じがあって素敵ですね。
名前大喜利がおもろくて定期的に見に行ってしまう #atmaCup 0.9行ける気がしてきた。・無理そうの流れが綺麗すぎて笑 pic.twitter.com/u59l38Nzpo
— nyker_goto (@nyker_goto) June 4, 2020
*1:スコアアップした時だけに現れる画面のことです。中毒性があるとの噂
atmaCup#5 開催レポート #atmaCup
はじめに
atmaCup、今回で6回目となりました。
今回はコロナウイルスの影響もあり初の完全オンライン参加での開催となりました。
参加者のレポ
参加者側の感想などはこちらをチェックください。
upura.hatenablog.com takaito0423.hatenablog.com agtn.hatenablog.com amalog.hateblo.jp nonbiri-tereka.hatenablog.com
いつもたくさんのレポありがとうございます。
開会式

atmaCup#5 開始致しました!!
— atma株式会社 (@atma_inc) 2020年5月29日
只今YoutubeLiveにて開催概要をライブ中です!!#atmaCup pic.twitter.com/Rk3jX2QOS5
今回新たに導入されたルール
チームコスト
チームの平等性を高めるべく、今回新たにチームマージ時にコストが必要となりました。またチームマージするとsubmission上限が増える特殊?ルールも追加されています。

なお、AutoMLはコスト100なので誰ともマージできません😢

序盤
atmaCup#5、開始から約1日経過したリーダーボードの状況はこちらです。
— atma株式会社 (@atma_inc) 2020年5月30日
まだ1日しか経過していないにも関わらず皆様高スコアで争ってます!!https://t.co/VOmLgf2xSs #atmaCup pic.twitter.com/WgWf66QDQd
初心者向け講座 #1
今回もデータコンペに参加したことがない・分析ははじめてという方向けに nyk510 から初心者向け講座を開催しました。
初心者向け講座#1は主にデータの見方についての講座で pandas profiling を使った可視化や波形データを t-SNE による低次元射影可視化して特徴を探る方法などを紹介しました。
初心者向け講座 #2
初心者向け講座 #2は実際にSubmissionするまでの講座でした。 LightGBMによる基本的なモデルの作り方 + 波形ならではの特徴を木構造にどう盛り込んでいくか、に関して深堀して解説しました。
atmaCup 初心者向け講座始まってますー。
— atma株式会社 (@atma_inc) 2020年6月3日
本日はSubmissonの作り方についてです。#atmaCup pic.twitter.com/JoWnwQZlls
データ不備について
#atmaCup 運営の不手際で、データに不備があり大変申し訳ありませんでした。slackとコンペのdiscussionにて内容と差し替え後のデータを配布していますので、お手数ですがご協力のほどよろしくお願いいたしますmm https://t.co/XPR9pTipKi
— nyker_goto (@nyker_goto) 2020年6月2日
#atmaCup また昨日のデータ差し替えについてです. なぜ起こったか,再発防止策を運営で話し合いました.最終日に報告させていただきます.
— nyker_goto (@nyker_goto) 2020年6月3日
水を差してしまいましたが,引き続きコンペを楽しんでいただけると幸いです🙇
中盤
atmaCup#5、開始から3日経過したリーダーボードの状況はこちらです。
— atma株式会社 (@atma_inc) 2020年6月1日
上位陣は0.9超えのハイスコアで競っています。
nyk510によるベースラインや、こっそりAutoMLも参戦しております。https://t.co/uQtoPtjDcv #atmaCup pic.twitter.com/t60TR2xf2E
すでに上位陣は0.9を超えるスコアで争っています。
終盤
atmaCup#5終了まで残り1時間を切りました! #atmaCup pic.twitter.com/VoPoMh8Tdt
— atma株式会社 (@atma_inc) 2020年6月6日
上位20位まで0.9超え、1位は0.93超えてます。
しかもKaggleRankはContributor以下のチームです。
閉会式
atmaCup#5終了いたしました。
— atma株式会社 (@atma_inc) 2020年6月6日
皆様お疲れさまでした。
現在、閉会式をおこなっております。 #atmaCup pic.twitter.com/WSN6jtihNZ
まとめ
 途中データの不備があり、お手数をおかけしましたが、無事に終了することができました。
途中データの不備があり、お手数をおかけしましたが、無事に終了することができました。
特に今回オンラインということもあってかdiscussionが大いに盛り上がりました。 ひとえに皆様のご協力があってatmaCupは成り立っております。
Next?
次回の開催も決定しております!!(日程は未定) 開催決まり次第Twitter等で告知させていただきます。
DRFとNuxtを使って画像分類(機械学習)をする①
はじめに
インターンしている小林です.この記事では,DRF(Djangoのいい感じのフレームワーク)を使って,APIを作るまで行います.記事は二編構成とし,一編はDRFによるAPI作成,二編はNuxtを用いてユーザが実際に入力することを想定してフロント作成します.具体的には,PyTorchのresnetを用いて,入力フォームから受け付けられた画像を推論して上位10位までの結果を表示させます.一編では,詳細な機械学習のアルゴリズムは説明せずに,APIを作る工程に重きを向けます.読者の対象はDRFを初めたての人が対象であり,機械学習の画像処理をある程度把握している人が対象となります.
構築したAPIは以下のような感じになります.
結果で返しているのはresnet-18に入力した画像を推論させ,確率値が高い上位10個を表示させています.用いてるモデルはImageNetの学習済みモデルです.
DRFについて
「Django」は Python で Webアプリケーションを作成するためフレームワークですが、「Django REST Framework」という Django のためのパッケージを使うことで、RESTful な API バックエンドを簡単に構築することができます。実際の現場では、SPA(シングルページアプリケーション)やスマホアプリのバックエンドとしてよく利用されています(引用:現場で使える Django REST Framework の教科書 (Django の教科書シリーズ))。とのことですが,基本的にはDjangoで足りない所を補ってやりたいというのが,これを使っている理由です.ただし,色々な機能があるため少し重たいファイルであることはデメリットですが,それを超える良い機能が複数あるので慣れると使いやすいものかと思われます.
目次
環境構築
環境構築は以下を基本として構築しました.
https://qiita.com/michio-k/items/371881a6b8ecfa768606
ファイル構成は以下のようになります.
home |- backend | |- core(Djangoのプロジェクトが入る) | |- app(APIを作成) | |- Dockerfile | |- requirements.txt |- front | |- nuxt (フロントのプロジェクト) | |- Dockerfile |- .gitignore |- docker-compose.yml |- README.md
今回操作するのは上記のbackendの方となります.二編目でfrontの方をいじっていきます.画像のAPIを作成する上で,いくつかインストールする必要があるモジュールがあるので,記していきます.
FROM python:3.7
ENV PYTHONUNBUFFERED 1
RUN mkdir /code
WORKDIR /code
RUN apt-get update && apt-get install -y \
libblas-dev \
liblapack-dev\
libatlas-base-dev \
libsm6 \
libxext6 \
libxrender-dev
ADD requirements.txt /code/
RUN pip install --upgrade pip
RUN pip install --no-cache-dir -r requirements.txt
インストールするpythonモジュールです.ここでは,django-jsonfieldを使って辞書のデータを受け付けるようにします.実務的になると,PostgresやMySQLを使う方がいいと思われるので,そちらをデータベースとして参照する方が望ましいです.今回は簡易的なものなので,これを使わず,sqlite(デフォルトの設定)でやっていきます.これらのことは後に後述します.
* 補足として,DjangoでPostgresやMySQLなどでデータベースを使用したいときは,以下のサイトを参考にしてください. qiita.com
*
画像分類の処理では今回はPyTorchを使っていきます.pillowはDRF(Django)が画像を読み込む時に必要となるのでインストールしておきます.
# backend/requirements.txt #Django django djangorestframework django-filter django-cors-headers django-jsonfield #Extra numpy pillow opencv-python torch torchvision
次にdocker-compose.ymlを記述します.以下の通りになります.
version: '3' services: #front: #container_name: front #build: ./front #tty: true #ports: # - '3000:3000' #volumes: #- ./front/:/usr/src/app # command: [sh, -c, "cd nuxt/ && npm run dev"] backend: container_name: backend build: ./backend tty: true ports: - '8000:8000' volumes: - ./backend:/code # command: python manage.py runserver 0.0.0.0:8000
これにて環境構築が終わりです.補足ですが,Dockerを使わなくてもrequirements.txtに記述してあるモジュールをインストールしている環境であるならば,これからやることはできます.また,下のコードで先程構築した環境に入ることができます.
docker-compose build #Dockerfileの環境を立ち上げる docker-compose up -d #起動 docker exec -it backend bash #containerの中に入る
DRFのモジュール作成
DRFのプロジェクトとアプリの作成
これからDjangoのプロジェクトを作成していきます.この方法は通常のDjangoのやり方と変わりません.
django-admin startproject core . python manage.py startapp app
にてファイルを作成します.次にcore内のsettings.pyに今回作ったファイルとDRFを読み込ませます.また,各種必要なものを記述しておきます.MEDIAは画像の保存先を指定するために必要となりますので追記してください.
#python:core/settings.py ALLOWED_HOSTS = ["localhost"] INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', "rest_framework", #add "app", #add ] #add MEDIA_URL = "/media/" MEDIA_ROOT = os.path.join(BASE_DIR,"media")
resnetのファイル
この記事での推論はresnetを使用します.また,簡易的なものであるため,自前の学習済みモデルを使用せずネット上に公開されているFinetuned-modelを利用します(ImageNetです).そのため,以下にしているファイルを事前にダウンロードしてください.
- https://download.pytorch.org/models/resnet18-5c106cde.pth
- https://github.com/raghakot/keras-vis/blob/master/resources/imagenet_class_index.json
以上で初期に用意するファイル一式の準備はできました.上記のファイルとresnet用に用意するファイルは以下のように作成してください.
backend ├── Dockerfile ├── app │ ├── __init__.py │ ├── admin.py │ ├── apps.py │ ├── models.py │ ├── resnet #add │ │ ├── config │ │ │ ├── imagenet_class_index.json │ │ │ └── resnet18-5c106cde.pth │ │ ├── model.py │ │ └── predict.py │ ├── tests.py │ └── views.py ├── core │ ├── __init__.py │ ├── asgi.py │ ├── settings.py │ ├── urls.py │ └── wsgi.py ├── manage.py └── requirements.txt
上記のようなファイル構成になっていると大丈夫です!
modelsの作成
今回APIとして必要になるのは以下の通りです.
- 入力:入力した画像の名前と入力する画像
- 出力:確率値が高い上位10までのラベル一覧と確率値
となります.そのため受け付けるフィールドは三つとなります.
#python:app/models.py from django.db import models import jsonfield # from django.contrib.postgres.fields import JSONField Jsonを受け付ける class ImageModel(models.Model): name = models.CharField(max_length = 128,null=True,default="unknown") image = models.ImageField(upload_to="media") predict = jsonfield.JSONField()
ここではjsonfieldというモジュールを使って,出力するための値を受け付けます.出力する値はjson形式にしたいのですが,Django内で提供されているJSONFieldはデータベースがpostgresやMySQLなどに対応しており,設定を変更しなければ使用できません.これはDjangoのデフォルトのデータベースがsqliteであり,対応していないためエラーが起こります.この問題を解決するために,今回は設定を省略し,jsonfieldというもので簡単にsqliteが受け付けられるようにしました.
また,今回作成したデータベースを登録するためにadminの内容を変更します.以下のように記述してください.
#app/admin.py from django.contrib import admin from .models import ImageModel @admin.register(ImageModel) class ImageModel(admin.ModelAdmin): pass
serializerの作成
続いてserializerの作成です.serializerはDRF特有のものであり,通常のDjangoにはありません.詳細は記事は以下のものが参考になるかと思いますので,乗せて起きます.
- https://note.crohaco.net/2018/django-rest-framework-serializer/
- https://www.django-rest-framework.org/api-guide/serializers/
- https://qiita.com/cohey0727/items/39308b67044391103d7f
やっていることは,入力されたデータの値がModelの中身で定義した型と一緒なのか?ということをやったり,Json形式で入力されたものをPythonで読み込めるようにしたりとそんなことをやっています.
appの直下にserializers.pyのファイルを作成し,以下のように記述します.
#app/serializers.py from rest_framework import serializers from .models import ImageModel class ImageSerializer(serializers.ModelSerializer): class Meta: model = ImageModel fields = ("id","name","image","predict") read_only_fields = ('predict',"id")
上記のように今回は書きました.入力としてはnameとimageのみなので,入力に必要ないものは外しています.また,上記のMetaに関する情報はhttps://teratail.com/questions/87695 が参考になるかと思いますので適宜参考にしてみてください.
viewsの作成
今回はDRFのビューはクラスベースビューを用いて,ModelViewSetを使って見ました.また,postを受け付けるコードをactionで対応するようにしました(これはdef post()メソッドを用いてもらっても大丈夫です).
#app/views.py from rest_framework import viewsets from rest_framework.response import Response from rest_framework.decorators import action from rest_framework import status from .models import ImageModel from .serializers import ImageSerializer from .resnet.predict import predict #resnetの予測 class ImageViewSet(viewsets.ModelViewSet): queryset = ImageModel.objects.all() serializer_class = ImageSerializer #check ユーザのどんなクエリを受け付けるか @action(detail=False,methods=["post"]) def classification(self,request): serializer = self.serializer_class(data = request.data) serializer.is_valid(raise_exception=True) img = request.data["image"] name = request.data["name"] res = predict(img) # 保存 item = ImageModel(name=name, image=img,predict = res) item.save() return Response(res, status=status.HTTP_200_OK)
serializer_classで受け付ける入力フォームを決めています.
@action(detail=False,methods=["post"]) def classification(self,request): serializer = self.serializer_class(data = request.data) serializer.is_valid(raise_exception=True) img = request.data["image"] name = request.data["name"] res = predict(img) # 保存 item = ImageModel(name=name, image=img,predict = res) item.save() return Response(res, status=status.HTTP_200_OK)
serializer = self.serializer_class(data = request.data)は入力されたデータが正しいかどうかを検証するためにいれています.極端な話,PDFのファイルが入力された時,エラーを出力してくれます.serializer.is_valid(raise_exception=True)を記述するとこの時点でエラーのデータがあるとエラーの文章で値が返されます.また,記述方法として,
if serializer.is_valid(): img = request.data["image"] name = request.data["name"] return Response(serializer.data,status=status.HTTP_200_OK) else: return Response(serializer.errors,status=status.HTTP_400_BAD_REQUEST)
があります.これは,if文章でTrueかFalseを処理して中身を実行するかどうかを判断しています.しかし,この書き方は若干情緒でもあるのでこれを省略しserializer.is_valid(raise_exception=True)だけを記述することで,上記のことと全く同じようにしてくれます.
ifの中身は,predict(img)でdictの結果を返してresで受け付けています.このresは先ほどの確率値の上位10個が入っている値の一覧が格納されています.これらのデータをItemModel()に入れ,保存しています.
urlの繋ぎこみ
繋ぎこみをします.app以下にurls.pyのファイルを作成して以下のように記述してください.
#app/urls.py from rest_framework import routers from .views import ImageViewSet router = routers.DefaultRouter() router.register(r"^image",ImageViewSet)
#core/urls.py from django.contrib import admin from django.urls import path,include from django.conf import settings from django.conf.urls.static import static from app.urls import router as router urlpatterns = [ path('admin/', admin.site.urls), path("",include(router.urls)) ] if settings.DEBUG: urlpatterns += static(settings.MEDIA_URL,document_root = settings.MEDIA_ROOT)
繋ぎこみの際にファイル名を注意してください.これでlocalhost:8000/image/classificationとURLを入れた時に,APIをPOSTできるようになります.
これでDRFで記述すべきことは終わりました.次に,resnetの方を記述していきます.
resnetの作成
resnetのディレクトリの中のmodel.pyを作成します.以下のように記述してください.
#app/resnet/model.py import torch from torchvision import models def resnet_model(): MODEL_PATH = "./app/resnet/config/resnet18-5c106cde.pth" model = models.resnet18(pretrained=False) model.load_state_dict(torch.load(MODEL_PATH)) model.eval() return model
今回は簡易的に作っているため,MODEL_PATHをこんな風にPathを書くことはナンセンスだと思うので注意してください(笑).また,model.eval()を忘れないでください(これを書くの忘れて何時間も悩んだのは裏の話).
次にpredict.pyを作成します.以下のように記述してください.
#app/resnet/predict.py from PIL import Image import json import cv2 import numpy as np import torch import torch.nn as nn from torchvision import transforms from .model import resnet_model preprocess = transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) ]) softmax = torch.nn.Softmax(dim=1) model = resnet_model() def predict(img): # json with open("./app/resnet/config/imagenet_class_index.json", 'r') as f: image_dict = json.load(f) # img img = Image.open(img) img = img.convert('RGB') img = np.array(img) img = preprocess(transforms.ToPILImage()(img)).unsqueeze(0) # prediction predict = model(img).data prob = softmax(predict)[0].tolist() best_ten = np.argsort(prob)[::-1][:10] response = [] for i,rank in enumerate(best_ten,1): label = image_dict[str(rank)][1] response.append({"rank":i,"prob":prob[rank],"label":label}) return response
入力された画像はImage.open(img)にて読み込みます.cv.imread(img)で読み込むことはできないので注意してください.また,
preprocess = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
この部分はImageNetの学習方法と同じようにしているので,これがなければ出力で欲しいラベルが返って来なくなります pytorch.org.
returnで返しているのは配列であり,中身は辞書型になっています.probの確率値はtolist()でリスト型にしています.これはデータベースにデータが保存されるときに,データの型がnumpyであるとエラーの原因になるためです(これはちょっとはまり所でした).そこで,tolist()で通常の数値型に変更し,エラーの原因を未然に防ぎます.参照したのは以下のページです.
APIを使って推論
ここまででAPIは作れたので,実際の画面で確認していきます.
python manage.py makemigrations python manage.py migrate
をしてください.これはDjangoの定型文みたいなものなので,そうなんだーみたいな感じでやってください(これはデータベースを作ってくれたりしている).また,Modelsの中身を変更したり,追加する場合は上記のコードをもう一度入力してください.すると,更新されます.
python manage.py runserver 0.0.0.0:8000
を実行しlocalhost:8000/imageのurlを検索すると以下のような画面が出てくると思います.

ここに保存されたデータの一覧が出力されるようになります.localhost:8000/image/classificationのurlを検索するとAPIをPOSTできる画面が出力されるのでやって見てください.
まとめ
今回は画像を入力として受け付けて,上位10個の確率値とラベルを出力するAPIを作成しました.モデルはresnetを使用し,ImageNetの学習済みモデルで値を出力させました.これらは適宜自分のモデルの差し替えが可能なので他のものでも試していきたいと思います.
次回
次はNuxtを利用して,front側を作成していきたいと思います.入力フォームを作成し,実際にユーザが画像を投稿するようなイメージで作成します.その画像をAPIに投げ,値が返ってくるところまでを実装し,画面に表示させます.